What we don’t talk about when we talk about AI
Dan Stanley, Executive Director at Future Narratives Lab reflects that current narratives around artificial intelligence (AI) are deeply influencing what is discussed. But shedding light on an overlooked truth could create a new, fairer story around the collective nature of data, its privatisation and extraction.
Little seems familiar in this bold new age of artificial intelligence (AI), but among the avalanche of announcements and barely credible claims, well established themes, dramatic in both tone and form, reliably recur.
Long before the specific technologies that hog today’s headlines were even conceived of, stories of robots, and the threat they represent, have regularly featured in our imaginative landscape. Humanoid machines, whether menacing terminators or more benevolent servants, remain the common visual accompaniment to AI discussions today. Metaphors of intelligent machines like these have a history almost as old as literature itself, right back from the automata of ancient epics like the Iliad, through legends of summoned Golems, to more modern imaginings of robot rebellion. Their persistence in culture reflects not only expanding technological capabilities, but recurring questions about the desire of humanity to expand its powers through invention, and the continuing fear that we might then lose control.
More generally, questions about intelligence, human nature, our relationship with machines, and our collective fate, are the perfect ingredients of compelling stories, serving often also as parables for our treatment of others. Beyond functioning as the foundation for our current cultural reception of AI, stories like these also continue to have direct influence on decision making at the highest level - one of the most significant acts regulating AI to be signed-off by any national government has been motivated, in part, by a leader having watched the latest ‘Mission: Impossible’ film.
AI then is a technology deeply entwined with ‘narrative’, not only through fictional stories and myths influencing its reception, but also the wider cultural structures, beliefs and ideologies that shape debate, and provide competing interpretations of the latest developments. ‘Narrative’ used in this sense refers to the layers of agendas, assumptions, mental models, and fundamental worldviews that make up collective understandings and social concepts, from everyday opinion to our deepest beliefs.
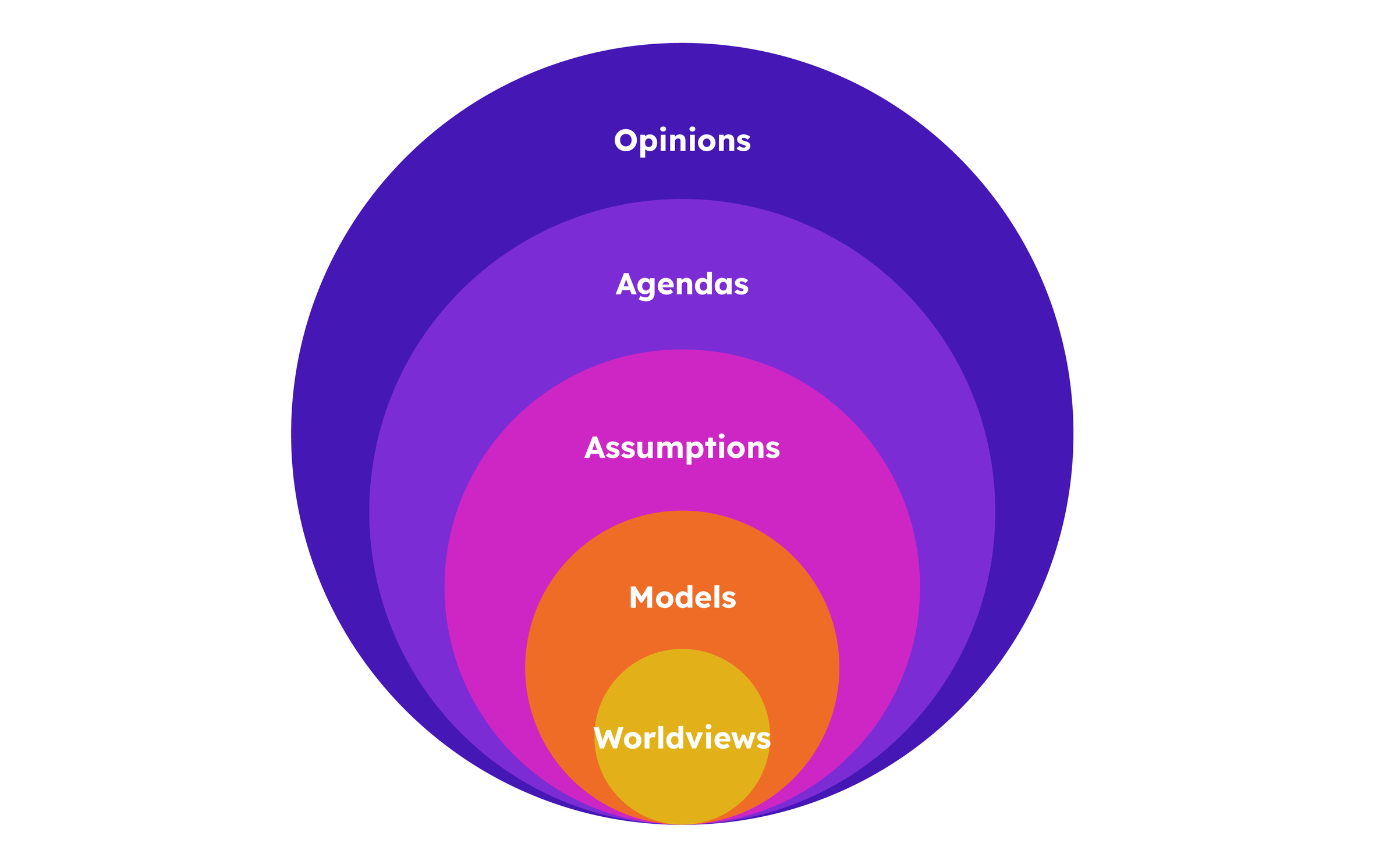
Most often this alternative sense of the term is employed to refer to particular agendas: efforts to ‘push a narrative’ that interprets events in favour of a particular perspective. But when it comes to AI, narratives of every level can be readily identified, and have influence on what is discussed, and whose opinion is seen as relevant.
What we do talk about
Recent debates about AI have been dominated by consideration of risk and safety, right up to the level of human extinction, and what regulatory response this might necessitate from governments. Set against this is speculation that AI could be a uniquely beneficial force for progress, capable of tackling our biggest collective problems, and unlocking unimaginable prosperity.
Counterintuitively, while these views might seem inherently opposed, those behind the technology have advocated for both points of view simultaneously. The common ground between them being that this is a force of unsurpassed power, complexity and importance, so those who created it must therefore be expert authorities to be consulted on the most optimal means of restriction or encouragement. Thus, an exploration of a deeper narrative level reveals an impact missed when only considering narratives closer to the surface.
Yet, disagreements at deeper levels do exist. People (sometimes called ‘Doomers’) convinced a self-improving intelligence could rapidly (and fatally) outstrip humans, argue for immediate and drastic countermeasures, right up to the point of airstrikes on data centres. Supporters of AI argue our greatest mistake would be not realising the possibilities that are being unlocked, and that over-regulation is therefore the biggest risk. At both extremes deeper belief systems, well established in Silicon Valley circles, are drawn on. These are sometimes referred to as the acronym ‘TESCREAL’, and at their core is a belief that a superintelligent AI is not far off, and that it will likely play a role in utopian or dystopian outcomes.
Undoubtedly, such beliefs have real practical impacts on the decisions and actions of key players. For example, the founders of OpenAI have been clear that their primary motivation was to find a safe way to manage the imminent arrival of a super-intelligence, likely to transform society such that money itself may become obsolete. However, as evocative and fascinating as these beliefs may be, the scope of their relevance can still be questioned, particularly when looking more closely at the things they seek to draw attention to, and away from.
Fundamentally, predominant narratives frame AI in a way that obscures and ignores important realities, making fair and real public engagement with the technology more difficult. Far too much is left unsaid; designated, intentionally, as unworthy of discussion.
What we don’t talk about
At the most practical level, the material costs of AI systems are rarely part of mainstream discourse, whether the vast (and expanding) use of energy, water and other resources, or how most generative AI systems rely heavily on huge amounts of poorly paid and badly treated labour in developing countries. The consequences of real uses of AI technologies are ignored by mainstream narratives, despite an authoritative field of researchers, often former employees of AI companies, documenting in detail the current impacts. Instead, speculation on future existential risk is favoured.
Yet for all the novelty of our current debates on future superintelligence, with their unfamiliar terminology and unusually mythic themes, at a deeper level they can be seen as quite familiar. This is not the first time that emergent monopolists in a burgeoning field have attempted to position themselves to capture the fruits of technological progress, employing an arsenal of trusty rhetorical approaches to boost their case. Once more, basic regulation is positioned as inherently opposed to necessary innovation, and the spectre of global competition as a justification for reducing ‘cumbersome’ safeguards and oversight.
The effectiveness of these approaches now comes not only from the appeal of their novel packaging and dramatic themes, but from how they draw on and reinforce deeply entrenched existing narratives about technology and the economy. Ignoring inconvenient externalities, presenting one version of progress as ‘inevitable’ with no alternatives, the idea of corporate CEOs as the sole legitimate authorities on effective economic policy - all of these have long been pillars of a ‘pro-business’, low-regulation argument. As in their previous incarnations, debates on such terms exclude the public and their interests, taking as a given that decisions about technology and its regulation are a purely technical concern, in which a knowledgeable elite calculate the optimal outcome, rather than a political contest and balancing of fair outcomes.
At every level, predominant AI narratives direct attention, energy and debate away from a true accounting of the costs and consequences of the whole system, excluding the public, and allowing already powerful people to capture value. If AI is to operate in the public interest, this must be reckoned with.
How might this be done? Well, there is one further fundamental truth ignored by current AI narratives, the illuminating of which might provide a basis for new and fairer narratives.
The power behind AI
Fundamental to the way that our latest generation of AI works is its ongoing and growing need for vast amounts of data to train its models. Such is the scale of this consumption, that already there are warnings that sources of data for this purpose might soon run out.
When this core characteristic is factored in, today’s AI, far from its portrayal as a singular and unique phenomenon, can be seen as an outgrowth and symptom of a much bigger trend - the ‘datafication’ of modern societies.
With their last round of innovations, many of the same Big Tech Companies likely to dominate the AI age - Meta, Google, Microsoft - built empires of online advertising, harvesting huge amounts of data. Consumers were given access to ‘free’ software at the cost of surveillance alongside targeting, measuring and extracting value from their every interaction. Despite the public distaste that ensued as the true costs became clear, such infrastructure remains largely in place; this is largely down to the effectiveness of data narratives promoted by those same companies.
Over the last 2 decades, a consistent effort has been made to reinforce the idea that our data is a personal asset and possession, something we can happily choose to trade away for benefit, which fundamentally belongs to each individual. Intentionally excluded from this was any sense that data could be owned and managed as a collective good. This ignores the reality that data is, now and to an increasing extent collective rather than individual in its relevance and impact, carrying information about groups and connections rather than discrete individuals, something that those making money from it are all too aware of.
Novel as this may seem, there are historical parallels, with clear similarities to previous instances where the seizure of common goods for private exploitation have been justified through their apparent lack of individual ownership, from enclosures of common land in the UK, to the declarations of settler colonialists that indigenous land was ‘terra nullius’: ‘nobody’s land’.
What makes these narratives around data particularly effective is that they promote individualistic exploitation, whilst also providing a ready-made critique, as a pressure vent for any backlash. ‘Personal privacy’ - framed as the protection of your precious individual data from a dangerous outside world - is proposed as the solution to worries about the data extraction economy and its results, with the tech companies, through their advertising, declaring themselves our allies in this fight to protect it. Again, in this framing the individual nature of data is taken as a given - and attempts at building collectivity are further undermined by presenting outside forces as threats.
Both sides of this narrative then preclude the idea of any collective approach to data that might allow the building of power that could threaten the tech companies’ business models. This narrative dominance explains why existing collective models of data governance, such as data commons and data trusts, continue to find it hard to gain real traction, or even comprehension, among the public and policy makers, let alone strong support at scale.
Here is the root of the issue. Mass consumption of readily available public data at little cost is fundamental to the extractive way that AI works, and our predominant narratives of data are vital to this. If we are going to be able to engage the public meaningfully in the root causes of AI systems and how they work, beyond sensationalist distractions, we need to build a public concept of data, as a collective, common good.
Re-commoning data
This is no easy task. Though common goods do continue to exist even within a heavily privatised economy, they are rarely recognised and celebrated as such, so there are few available and effective metaphors. Data remains a profoundly ephemeral thing, with little presence in our imagination beyond strings of numbers, or the immediate mundane experiences of day-to-day storage and transmission quantities.
However, the rise of AI may provide opportunities to foreground the collective nature of data, and its privatisation and extraction. The sheer appetite of AI technology for data has inevitably led to lines being crossed, with various lawsuits under way where contravention of copyright and other possible infringements have been identified. While the legal actions themselves are unlikely to provide lasting progress, such public conflict does bring the real nature of AI and its extractive relationship to data more clearly into the public consciousness.
To build on these opportunities much needs to be done, and from the ground up. Those most excluded from the conversations about AI and technology must be part of a process of building new ways of conceiving of AI, as the product of a ‘datafied’ society. Any new narrative about AI and data will only be successful if it speaks to their concerns and realities, building an understanding that makes sense to them, with them.
A new alternative also needs to be built from an understanding of the narratives at play at every level, avoiding the trap of falling back into policy debates taking place within the terms of existing terrain, or the back-and-forth on the most obvious agendas of regulation and risk. Deeper analysis can uncover both the foundational weaknesses of existing AI and data narratives, and where the most promising opportunities lie to build narratives that speak to people’s values and identities.
This will not be quick work, with immediate results, but it can provide the foundations for long-term change, and a fundamentally different way of thinking about and managing AI, and indeed data and technology more widely. If we do want a better way to talk about AI, we need to build a new conversation, with a broader gaze, and a more ambitious imagination.

This reflection is part of the AI for public good topic.
Find out more about our work in this area.